引言
我为什么要写或者基于啥目的要写这篇文章? -- 为了面试备忘,在面试中吃了太多MySQL八股文的亏了。
1. 一条查询SQL是如何被执行的?
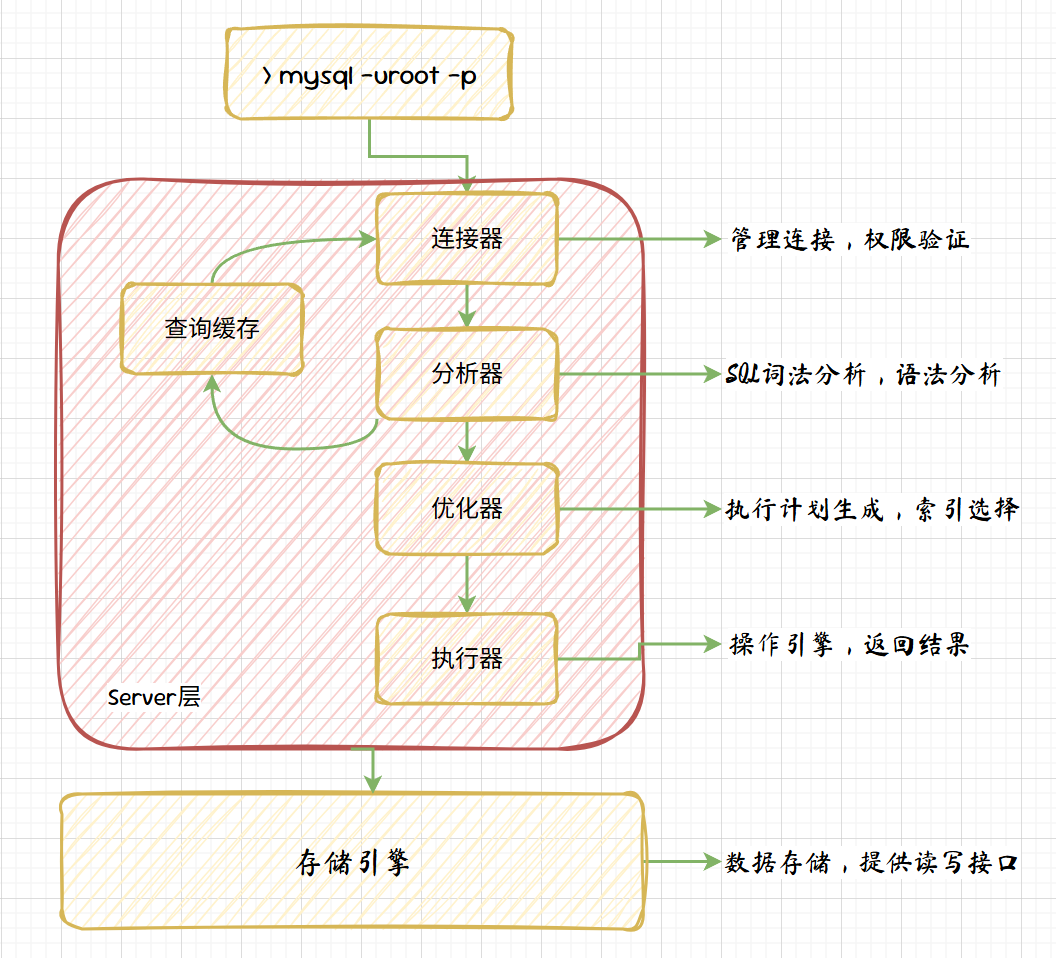
- 连接器
mysql客户端和服务端完成经典的TCP握手后,连接器就开始进行身份认证,如果用户名密码认证通过,连接器会到权限表里面查出你拥有的权限。之后,这个连接里面的权限判断逻辑,都将依赖于此时读到的权限。这就意味着,一个用户成功建立连接后,即使你用管理员账号对这个用户的权限做了修改,也不会影响已经存在连接的权限。修改完成后,只有再新建的连接才会使用新的权限设置。客户端如果太长时间没动静,连接器就会自动将它断开。这个时间是由参数wait_timeout控制的,默认值是8小时。
- 查询缓存
MySQL拿到一个查询请求后,会先到查询缓存看看,之前是不是执行过这条语句。之前执行过的语句及其结果可能会以key-value对的形式,被直接缓存在内存中。key是查询的语句,value是查询的结果。如果你的查询能够直接在这个缓存中找到key,那么这个value就会被直接返回给客户端。 查询缓存往往弊大于利,查询缓存的失效非常频繁,只要有对一个表的更新,这个表上所有的查询缓存都会被清空。需要注意的是,MySQL 8.0版本直接将查询缓存的整块功能删掉了。
- 分析器
分析器先会做“词法分析”。你输入的是由多个字符串和空格组成的一条SQL语句,MySQL需要识别出里面的字符串分别是什么,代表什么。做完了这些识别以后,就要做“语法分析”。根据词法分析的结果,语法分析器会根据语法规则,判断你输入的这个SQL语句是否满足MySQL语法,之后进入语义分析阶段,MySQL 对语法树进行进一步的分析和验证,包括验证列和表的存在性、数据类型的匹配、约束条件的合法性等。。
- 优化器
在执行SQL之前,需要先通过优化器处理。优化器是在表里面有多个索引的时候,决定使用哪个索引;或者在一个语句有多表关联(join)的时候,决定各个表的连接顺序。比如你执行下面这样的语句,这个语句是执行两个表的join:
mysql> select * from t1 join t2 using(ID) where t1.c=10 and t2.d=20;
- 既可以先从表t1里面取出c=10的记录的ID值,再根据ID值关联到表t2,再判断t2里面d的值是否等于20。
- 也可以先从表t2里面取出d=20的记录的ID值,再根据ID值关联到t1,再判断t1里面c的值是否等于10。
这两种执行方法的逻辑结果是一样的,但是执行的效率会有不同,而优化器的作用就是决定选择使用哪一个方案。
- 执行器
通过优化器知道了该怎么做,于是就进入了执行器阶段,开始执行语句。开始执行的时候,要先判断一下你对这个表T有没有执行查询的权限,如果没有,就会返回没有权限的错误。如果有权限,就打开表继续执行。打开表的时候,执行器就会根据表的引擎定义,去使用这个引擎提供的接口。
2. 一条更新SQL语句如何执行?
更新流程除了涉及到1. 一条查询SQL是如何被执行的?中所说的步骤外,还涉及到三个重要的日志模块操作,他们是Binlog归档日志、Redo log重做日志、Undo Log回滚日志。
假设有一数据:
{
"id": 1,
"name": "Bob"
}
- 客户端发起UPDATE请求, 当该记录所在页不在Buffer Pool中时,先加载该数据对应的数据页到Buffer Pool中,该过程会出发磁盘I/O,否则直接进行下一步。
UPDATE users SET name = 'Alice' WHERE id = 1;
- 写入Undo Log保证原子性与MVCC,具体做法是在修改数据前,InnoDB 会将当前行的旧值(name='Bob')复制到Undo Log中,Undo Log记录中包涵旧数据(用于回滚),事务ID(TRX_ID),回滚指针(ROLL_PTR)指向之前的 Undo Log,形成版本链。
- 修改 Buffer Pool中的数据页
name字段更新为'Alice',此时数据页仍在内存中,尚未刷盘,称为 脏页(Dirty Page)。 - 写入 Redo Log Buffer(保证持久性),在修改数据页的同时,InnoDB 会生成一条 Redo Log 记录,描述“在某个数据页的某个偏移量处做了何种修改”,该 Redo Log 先写入内存中的 Redo Log Buffer,此时 Redo Log 尚未写入磁盘,因此事务还未保证持久性。
- 事务提交时刷 Redo Log,当执行 COMMIT 时,InnoDB 会调用 fsync() 将 Redo Log Buffer 中与该事务相关的所有 Redo Log 记录顺序写入 Redo Log 文件(通常是 ib_logfile0、ib_logfile1),此时redo log中该数据的状态为prepare。
- 写入 Binlog,将事务的 SQL 语句(或行变更)写入 Binlog 文件,之后 Binlog 刷盘。
- 将事务的 Redo Log 标记为 COMMIT 状态,并刷盘,事务提交完成,客户端收到成功响应。
- 后台异步刷脏页,提交完成后,内存中的脏页(修改后的数据页)会在以下时机刷回磁盘,1是Checkpoint 机制触发,2是Redo Log 写满时(循环写入),3是空闲时或关闭数据库时。脏页刷盘后,该数据页的修改才真正持久化到表数据文件(.ibd)。
3. 事务崩溃恢复流程
如果 MySQL 在事务提交过程中崩溃,重启时会按以下逻辑恢复:
- 扫描 Redo Log:找到所有 PREPARE 状态的事务。
- 检查 Binlog:如果事务的 Binlog 已完整写入,则重做(Redo)该事务(提交)。
- 如果 Binlog 不存在:则回滚(Undo)该事务。
4. count聚合函数性能
count()是一个聚合函数,对于返回的结果集,一行行地判断,如果count函数的参数不是NULL,累计值就加1,否则不加。最后返回累计值。
- 对于count(主键id)来说,InnoDB引擎会遍历整张表,把每一行的id值都取出来,返回给server层。server层拿到id后,判断是不可能为空的,就按行累加。
- 对于count(字段)来说,如果这个“字段”是定义为not null的话,一行行地从记录里面读出这个字段,判断不能为null,按行累加;如果这个“字段”定义允许为null,那么执行的时候,判断到有可能是null,还要把值取出来再判断一下,不是null才累加。
- 对于count(1)来说,InnoDB引擎遍历整张表,但不取值。server层对于返回的每一行,放一个数字“1”进去,判断是不可能为空的,按行累加。
- 对于count(*)来说,并不会把全部字段取出来,而是专门做了优化,不取值。count(*)肯定不是null,按行累加。
所以结论是:按照效率排序的话,count(字段) < count(主键id) < count(1) ≈ count(*),尽量使用count(*)。
3. 什么是redo log
4. 什么是binlog
5. 什么是undo log
6. 什么是reply log
7. 锁
8. 索引
9. 事务隔离
10. SQL优化
11. 如何保证数据不丢
12. 如何保证主备一致
13. 如何保证高可用
14. 如何保证主备一致
| 差别 | binlog | redolog |
|---|---|---|
| 层级 | server层 | innodb引擎层 |
| 范围 | 逻辑日志 | 物理日志 |
B树与B+树的区别
B树叫多路平衡搜索树,每个节点可以存储多个数据,存储数据的个数由B树的度决定。
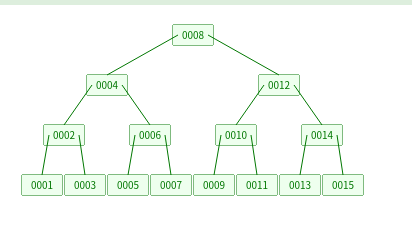
B+树是B树的一种变形,B+树元素自底向上插入,这与二叉树恰好相反,所有的数据都存储在叶子节点上,非叶子节点的数据都是叶子节点数据的冗余。叶子节点之间的数据通过指针连接。
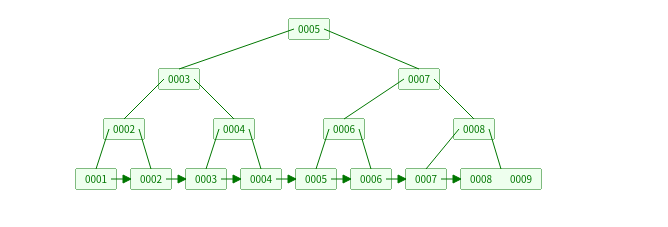
绘图工具: https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
为什么不用B树而用B+树
-
B树不适合范围查找 比如我要查找小于6的数据,则先找到6的节点,然后需要遍历一遍6节点(索引)的左子树,不遍历的话,就拿不到小于6的这些数据了,也就说索引失效了,所以说不适合范围查找。
-
页大小和稳定性的考量 B树的节点除了存储索引之外,还存储了数据本身,占用空间较大,但是磁盘的页大小是有限的(16KB左右),因此,存储同样大小的数据,BTree显得比较高(相对B+Tree),稳定性弱一些。
高度为N的B+树可以存多少条数据
树高度等于2时(2阶),如果记录大小为1KB,以INT类型为索引:
页编号(索引页)大小:page_size(16kb) / (index_type_size(4byte)+page_dir_pointer(6byte)) = 16kb/10b .= 1638
意味着2阶B+树可以存储约1638个页,每页数量(数据页)为 16kb/1kb = 16,得2阶B+树可以存数据 = 16*1638 = 26208
高度等于3时(3阶)时:
一级页编号大小 1638,二级页编号大小 = 1638^2, 得3阶B+树可以存数据 = 16*1638^2 = 42928704
幻读与不可重复读
我一直以来都把幻读理解为了不可重复读。此话怎讲?
以前的观念:
幻读是 事务A 执行两次 select 操作得到不同的数据集,即 select 1 得到 10 条记录,select 2 得到 15 条记录。
这其实并不是幻读,既然第一次和第二次读取的不一致,那不还是不可重复读吗,所以这是不可重复读的一种。
现在的观念:
幻读,并不是说两次读取获取的结果集不同,幻读侧重的方面是某一次的 select 操作得到的结果所表征的数据状态无法支撑后续的业务操作。更为具体一些:select 某记录是否存在,不存在,准备插入此记录,但执行 insert 时发现此记录已存在,无法插入,此时就发生了幻读。
引用自: 一文详解脏读、不可重复读、幻读
explain 温习
在复习索引之前,有必要再温习记录一下 explain 这个SQL查询优化器能给我们哪些索引优化的提示。
诸如在某次执行后的结果集如下:
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | course | range | PRIMARY | PRIMARY | 4 | 9 | Using where |
id : select查询的序列号,包含一组数字,表示查询中执行select子句或操作表的顺序 table :正在访问哪个表 通过 id 与 table 字段可以得知子查询何连表查询等的查表顺序。 select_type : 查询类型。
- SIMPLE 简单查询。
- PRIMARY 当存在子查询时,最外面的查询被标记为主查询。
- SUBQUERY 子查询。
- UNION 当一个查询在UNION关键字之后就会出现UNION。
- UNION RESULT 连接几个表查询后的结果
type :访问的类型。
NULL: 在执行阶段用不着再访问表或索引
system:查系统表
const:通过索引一次就找到了(直接按主键或唯一键读取)
eq_ref:主键或唯一键联合查询
ref:非唯一性索引扫描
ref_or_null:类似ref,但是可以搜索值为
NULL的行 index_merge:查询使用了两个以上的索引,最后取交集或者并集 range:索引范围查询 index:index只遍历索引树,通常比All快。因为,索引文件通常比数据文件小,也就是虽然all和index都是读全表,但index是从索引中读取的,而all是从硬盘读的。 ALL:如果一个查询的type是All,并且表的数据量很大,那么请解决它!!!
possible_keys :显示可能应用在这张表中的索引,一个或多个,但不一定实际使用到 key : 实际使用到的索引,如果为NULL,则没有使用索引 key_len :表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度 ref:显示索引的哪一列被使用了,如果可能的话,是一个常数,哪些列或常量被用于查找索引列上的值 rows: 根据表统计信息及索引选用情况,大致估算出找到所需的记录所需读取的行数 Extra:包含不适合在其它列中显示但十分重要的额外信息
- Using filesort 对没有建立索引的字段进行排序
- Using tempporary对MySQL查询结果进行排序时,使用了临时表,这样的查询效率是比外部排序更低的,常见于
order by和group by。 - Using index表示使用了索引
- Using where可能全表扫描;可能回表读数据 然后过滤;
- Using Index Condition先条件过滤索引,过滤完索引后找到所有符合索引条件的数据行,随后用 WHERE 子句中的其他条件去过滤这些数据行;
innodb是如何支持查询时走索引的
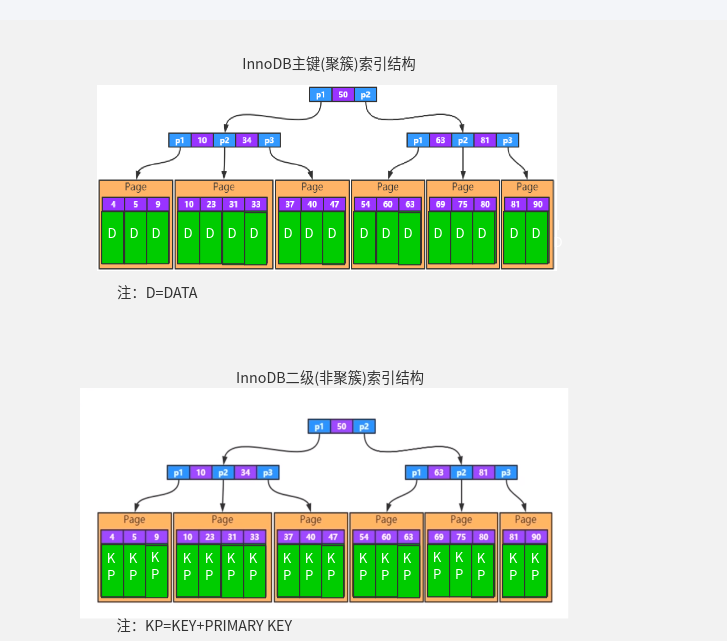
innodb 数据的数据页间通过双向链表连接,数据页内数据通过单向链表连接,类似 between and > < 都是利用了数据页间的双向链表完成的。
最左前缀原则下的索引问题
对于联合索引,通过最左前缀原则指导搜索。例如 a为主键, bcd组合成联合索引,那么对于以下情况:
select * from user where b = 1 and c = 1 and d = 1; -- 走索引
select * from user where b = 1 and c = 1; -- 走索引
select * from user where b = 1 and d = 1; -- 不走索引
select * from user where c = 1 and d = 1; -- 不走索引
order by 为何导致索引失效
并不是说使用了 order by 就一定不走索引。 不使用 order by 时,结果集按照默认升序进行结果输出,当 order by 介入并不按照给定索引进行排序,就会导致额外文件排序。所谓的索引失效主要是说额外的Using filesort,因为走索引时,且order by按照索引顺序进行,并利用覆盖索引方式进行查找,是不会带来 Using filesort 的开销的。
必定导致 Using filesort 的 order by 情况有如下
-- 依然是 a 为主键索引 bcd为联合索引
explain SELECT b,c,d from course order by b, c, d; //Using index
-- 未按照最佳左前缀原则进行 order by
explain SELECT b,c,d from course order by c, d; // Using index; Using filesort
-- where 中使用最佳左前缀为条件
explain SELECT b,c,d from course where b = 1 order by c, d; // Using where; Using index
explain SELECT b,c,d from course where c = 2 order by b, d; //
-- order by 中同时包含 asc, desc 一定会 using filesort
explain SELECT b,c,d from course where b = 1 order by c asc, d desc; // Using where; Using index; Using filesort
小结一下失效原因:
-
字段排序不一致
-
最佳左前缀丢失
-
字段不是索引的一部分